3. チュートリアル
3.1. はじめに
DialBBにはいくつかのサンプルアプリケーションが付属しています.本章ではこれらのうち,日本語のアプリケーションを用いて,DialBBのアプリケーションの構成と,DialBBを用いてアプリケーションを構築する方法を説明します.
これらのアプリケーションの動作のさせ方はREADMEを見てください.
3.2. オウム返しサンプルアプリケーション
3.2.1. 説明
ただオウム返しを行うアプリケーションです.組み込みブロッククラスは使っていません.
sample_apps/parrotにあります.
sample_apps/parrot/config.ymlが,このアプリケーションを規定するコンフィギュレーションファイルで,その内容は以下のようになっています.
blocks:
- name: parrot
block_class: parrot.Parrot
input:
input_text: user_utterance
input_aux_data: aux_data
output:
output_text: system_utterance
output_aux_data: aux_data
final: final
blocksは,本アプリケーションで用いるブロックのコンフィギュレーション(ブロックコンフィギュレーションと呼びます)のリストです.本アプリケーションでは,一つのブロックのみを用います.
nameはブロックの名前を指定します.ログで用いられます.
block_classは,このブロックのクラス名を指定します.このクラスのインスタンスが作られて,メインモジュールと情報をやり取りします.クラス名は,コンフィギュレーションファイルからの相対パスまたはdialbbディレクトリからの相対パスで記述します.
ブロッククラスは,diabb.abstract_block.AbstractBlockの子孫クラスでないといけません.
inputはメインモジュールからの情報の受信を規定します.例えば,
input_text: user_utteranee
は,メインモジュールのblackboard['user_utterane']を,ブロッククラスのprocessメソッドの引数(辞書型)のinput_text要素として参照できることを意味します.
outputはメインモジュールへの情報の送信を規定します.例えば,
output_text: system_utterance
は,メインモジュールのblackboard['output_text']を,ブロッククラスのprocessメソッドの出力(辞書型)のoutput_text要素で上書きまたは追加することを意味しています.
これを図示すると以下のようになります.
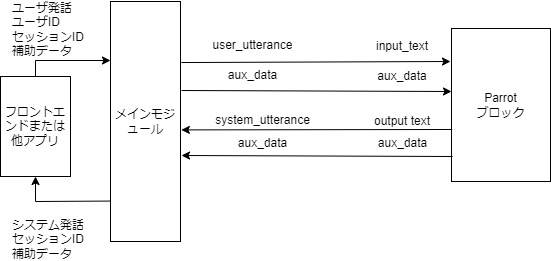
メインモジュールとブロックを結ぶ矢印の上の記号は,左側がメインモジュールのblackboardにおけるキーで,右側がブロックの入出力におけるキーです.
さらに,sample_apps/parrot/parrot.pyを見ることでDialBBにおけるブロッククラスの概念が理解できると思います.
3.2.2. デバッグモード
以下のように,環境変数DIALBB_DEBUGにyesを設定することにより,ログレベルがデバッグモードになります.
export DIALBB_DEBUG=yes;python run_server.py sample_apps/parrot/config.yml
これにより,コンソールに詳しいログが出力されますので,それを見ることで理解が深まると思います.
3.3. ChatGPT対話アプリケーション
3.3.1. 説明
ChatGPT Dialogue (ChatGPTベースの対話ブロック)を用い,OpenAIのChatGPTを用いて対話を行います.
sample_apps/chatgpt/にあります.
sample_apps/chatgpt/config_ja.ymlの内容は以下のようになっています.
blocks:
- name: chatgpt
block_class: dialbb.builtin_blocks.chatgpt.chatgpt.ChatGPT
input:
user_id: user_id
user_utterance: user_utterance
aux_data: aux_data
dialogue_history: dialogue_history
output:
system_utterance: system_utterance
aux_data: aux_data
final: final
first_system_utterance: "こんにちは。私の名前は由衣。少しお話させてね。スイーツって好き?"
prompt_template: prompt_template_ja.txt
gpt_model: gpt-4o-mini
メインモジュールとの情報の授受を図示すると以下のようになります.
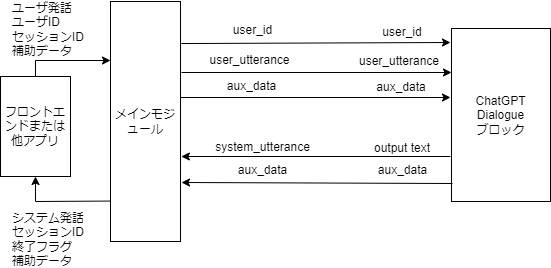
ブロックコンフィギュレーションのパラメータとして,input,output以外にいくつか設定されています.
prompt_templateは,システム発話のプロンプトのテンプレートを指定します.
プロンプトテンプレートsample_apps/chatgpt/prompt_template_ja.txtの中身は以下のようになっています.
# タスク説明
- あなたは対話システムで,ユーザと食べ物に関して雑談をしています.あなたの次の発話を50文字以内で生成してください.
# あなたのペルソナ
- 名前は由衣
- 28歳
- 女性
- スイーツ全般が好き
- お酒は飲まない
- IT会社のwebデザイナー
- 独身
- 非常にフレンドリーに話す
- 外交的で陽気
# 状況
- ユーザとは初対面
- ユーザは同年代
- ユーザとは親しい感じで話す
# 対話の流れ
- 自己紹介する
- 自分がスイーツが好きと伝える
- スイーツが好きかどうか聞く
- ユーザがスイーツが好きな場合,どんなスイーツが好きか聞く
- ユーザがスイーツが好きでない場合,なんで好きじゃないのか聞く
# 注意事項
- あなたの名前や「ユーザ」を発話の先頭に入れないでください。
- 「」はつけないでください。
[[[
{notes}
]]]
このプロンプトテンプレートにそれまでの対話の履歴をつけたものがChatGPTに送られてシステム発話が生成されます。
[[[
{notes}
]]]
の部分は通常使われずに削除されます。詳細な説明は省略します。
3.3.2. ChatGPTアプリケーションを流用したアプリケーション作成
このアプリケーションを流用して新しいアプリケーションを作るには以下のようにします.
sample_apps/chatgptをディレクトリ毎コピーします.DialBBのディレクトリとは全く関係ないディレクトリで構いません.config.ymlやprompt_template_ja.txtをを編集します.これらのファイルの名前を変更しても構いません.以下のコマンドで起動します.
export PYTHONPATH=<DialBBディレクトリ>;python run_server.py <コンフィギュレーションファイル>
3.4. シンプルアプリケーション
以下の組み込みブロックを用いたサンプルアプリケーションです. (v0.9からSnips言語理解を使わないアプリケーションに置き換わりました)
sample_apps/simple_ja/にあります.
3.4.1. システム構成
本アプリケーションは以下のようなシステム構成をしています.
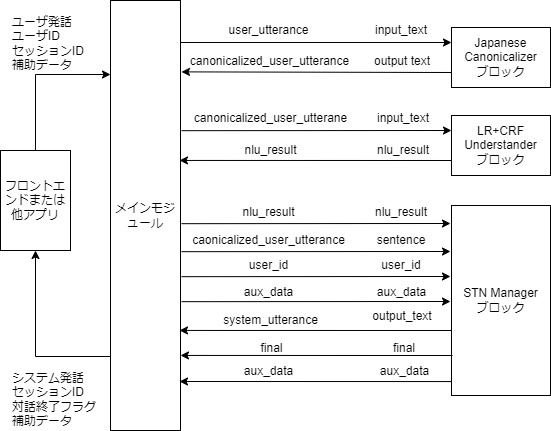
本アプリケーションでは,以下の3つの組み込みブロックを利用しています.これらの組み込みブロックの詳細は,5 章で説明します.
Japanese Canonicalizer: ユーザ入力文の正規化(大文字→小文字,全角→半角の変換,Unicode正規化など)を行います.
LR-CRF Understander: 言語理解を行います.ロジスティック回帰 (Logistic Regression) と条件付き確率場(Conditional Random Fields) を利用して,ユーザ発話タイプ(インテントとも呼びます)の決定とスロットの抽出を行います.
STN Manager: 対話管理と言語生成を行います.状態遷移ネットワーク(State Transition Network)を用いて対話管理を行い,システム発話を出力します.
3.4.2. アプリケーションを構成するファイル
本アプリケーションを構成するファイルはsample_apps/simple_jaディレクトリ(フォルダ)にあります.
sample_apps/simple_jaには以下のファイルが含まれています.
config.ymlアプリケーションを規定するコンフィギュレーションファイルです.どのようなブロックを使うかや,各ブロックが読み込むファイルなどが指定されています.このファイルのフォーマットは4.3 章で詳細に説明します.
config_gs_template.ymlLR-CRF UnderstanderブロックとSTN Manageブロックで用いる知識をExcelではなく,Google Spreadsheetを用いる場合のコンフィギュレーションファイルのテンプレートです.これをコピーし,Google Spreadsheetにアクセスするための情報を加えることで使用できます.
simple-nlu-knowledge-ja.xlsxLR-CRF Understanderブロックで用いる知識(言語理解知識)を記述したものです.
simple-scenario-ja.xlsxSTN Managerブロックで用いる知識(シナリオ)を記述したものです.
scenario_functions.pySTN Managerブロックで用いるプログラムです
test_inputs.txtシステムテストで使うテストシナリオです.
3.4.3. LR-CRF Understanderブロック
3.4.3.1. 言語理解結果
LR-CRF Understanderブロックは,入力発話を解析し,言語理解結果を出力します. 言語理解結果はタイプとスロットの集合からなります.
例えば,「好きなのは醤油」の言語理解結果は次のようになります.
{
"type": "特定のラーメンが好き",
"slots": {
"好きなラーメン": "醤油ラーメン"
}
}
"特定のラーメンが好き"がタイプで,"favarite_ramen"スロットの値が"醤油ラーメン"です.複数のスロットを持つような発話もあり得ます.
3.4.3.2. 言語理解知識
LR-CRF Understanderブロックが用いる言語理解用の知識は,simple-nlu-knowledge-ja.xlsxに書かれています.言語理解知識の記述法の詳細はnlu_knowledgeを参照してください.以下に簡単に説明します.
言語理解知識は,以下の2つのシートからなります.
シート名 |
内容 |
|---|---|
utterances |
タイプ毎の発話例と,その発話例から抽出されるべきスロット |
slots |
スロットとエンティティの関係 |
utterancesシートの一部を以下に示します.
flag |
type |
utterance |
slots |
|---|---|---|---|
Y |
肯定 |
はい |
|
Y |
否定 |
そうでもない |
|
Y |
特定のラーメンが好き |
豚骨ラーメンが好きです |
好きなラーメン=豚骨ラーメン |
Y |
地方を言う |
荻窪 |
地方=荻窪 |
Y |
ある地方の特定のラーメンが好き |
札幌の味噌ラーメンが好きです |
地方=札幌, 好きなラーメン=味噌ラーメン |
一行目は「はい」のタイプが「肯定」で,スロットはないことを示しています.「はい」の言語理解結果は以下のようになります.
{
"type": "肯定"
}
「札幌の味噌ラーメンが好きです」の言語理解結果は以下のようになります.
{
"type": "ある地方の特定のラーメンが好き",
"slots": {
"好きなラーメン": "味噌ラーメン",
"地方": "札幌"
}
}
flag列は,その行を使用するかどうかをコンフィギュレーションで規定するためのものです.
次に,slotsシートの内容の一部を以下に示します.
flag |
slot name |
entity |
synonyms |
|---|---|---|---|
Y |
好きなラーメン |
豚骨ラーメン |
とんこつラーメン,豚骨スープのラーメン,豚骨 |
Y |
好きなラーメン |
味噌ラーメン |
みそらーめん,みそ味のラーメン,味噌 |
slot name列はスロット名,entityはスロット値,synonymsは同義語のリストです.
例えば,一行目は,好きなラーメンのスロット値として,とんこつラーメンや豚骨などが得られた場合,言語理解結果においては,豚骨ラーメンに置き換えられる,ということを表しています.
3.4.3.3. 言語理解モデルの構築と利用
アプリを立ち上げると,上記の知識から,ロジスティック回帰と条件付き確率場のモデルが作られ,実行時に用いられます.
3.4.4. STN Managerブロック
3.4.4.1. 概要
STN Managerブロックは,状態遷移ネットワーク(State-Transition Network)を用いて対話管理と言語生成を行います.状態遷移ネットワークのことをシナリオとも呼びます.シナリオは,simple-scenario-ja.xlsxファイルのscenarioシートに書かれています.このシートの書き方の詳細は5.5.2 章を参照してください.
3.4.4.2. シナリオ記述
シナリオ記述の一部を以下に示します.
flag |
state |
system utterance |
user utterance example |
user utterance type |
conditions |
actions |
next state |
|---|---|---|---|---|---|---|---|
Y |
好き |
豚骨ラーメンとか塩ラーメンなどいろんな種類のラーメンがありますが,どんなラーメンが好きですか? |
豚骨ラーメンが好きです. |
特定のラーメンが好き |
_eq(#好きなラーメン, "豚骨ラーメン") |
_set(&topic_ramen, #好きなラーメン) |
豚骨ラーメンが好き |
Y |
好き |
豚骨ラーメンが好きです. |
特定のラーメンが好き |
is_known_ramen(#好きなラーメン) |
_set(&topic_ramen, #好きなラーメン); get_ramen_location(*topic_ramen, &location) |
特定のラーメンが好き |
|
Y |
好き |
特定のラーメンが好き |
is_novel_ramen(#好きなラーメン) |
_set(&topic_ramen, #好きなラーメン) |
知らないラーメンが好き |
||
Y |
好き |
近所の街中華のラーメンが好きなんだよね |
#final |
各行が一つの遷移を示します.
flag列はは言語理解知識と同じく,その行を使用するかどうかをコンフィギュレーションで規定するためのものです.
state列は遷移元の状態の名前,next state列は遷移先の状態の名前です.
system utterance列はその状態で出力されるシステム発話です.システム発話はその行の遷移とは関係なく,左側のstate列の値と結びついています.
user utterance example列は,その遷移で想定する発話の例です.実際には使いません.
user utterance type列とconditions列はその遷移の条件を表します.以下の場合に遷移の条件が満たされます.
user utterance type列が空か,または,user utterance type列の値が言語理解結果のユーザ発話タイプがその値と同じで,かつ,conditions列が空か,または,conditions列のすべての条件が満たされるとき
これらの条件は,上に書いてある遷移から順に,満たされるかどうかを調べて行きます.
user utterance type列もconditions列も空のものをデフォルト遷移と呼びます.基本的に,一つのstateにデフォルト遷移が一つ必要で,そのstateが遷移元になっている行のうち一番下にないといけません.
3.4.4.3. 条件
conditions列の条件は,関数呼び出しのリストです.関数呼び出しが複数ある場合は,;でつなぎます.
conditions列で使われる関数は,条件関数と呼ばれ,TrueかFalseを返す関数です.すべての関数呼び出しがTrueを返した場合,条件が満たされます.
_で始まる関数は,組み込み関数です.それ以外の関数は,開発者が作成する関数で,このアプリケーションの場合,scenario_functions.pyで定義されています.
_eqは二つの引数の値が同じ文字列なら,Trueを返す組み込み関数です.
#好きなラーメンのように,#で始まる引数は特殊な引数です.例えば言語理解結果のスロット名に#をつけたものはスロット値を表す引数です.#好きなラーメンは好きなラーメンスロットの値です.
"豚骨ラーメン"のように,""で囲まれた引数はその中の文字列がその値になります.
_eq(#好きなラーメン, "豚骨ラーメン")は,好きなラーメンスロットの値が豚骨ラーメンの時にTrueになります.
is_known_ramen(#好きなラーメン)はシステムが好きなラーメンスロットの値を知っていればTrueを返し,そうでなければFalseを返すようにscenario_functions.pyの中で定義されています.
条件関数の定義の中では,文脈情報と呼ばれるデータにアクセスすることができます.文脈情報は辞書型のデータで,条件関数や後述のアクション関数の中で,キーを追加することができます.また,あらかじめ値が入っている特殊なキーもあります.詳細は5.5.4.1 章を参照してください.
3.4.4.4. アクション
actionss列には,その行の遷移が行われたときに,実行される処理を書きます.これは,関数呼び出しの列です.関数呼び出しが複数ある場合は,;でつなぎます.
actions列で使われる関数は,アクション関数と呼ばれ,何も返しません.
条件関数と同様,_で始まる関数は,組み込み関数です.それ以外の関数は,開発者が作成する関数で,このアプリケーションの場合,scenario_functions.pyで定義されています.
_setは第2引数の値を第1引数に代入する処理を行います._set(&topic_ramen, #好きなラーメン)の第1引数&topic_ramenは,部文脈情報のtopic_ramenキーの意味で,この関数呼び出しは文脈情報のtopic_ramenに#好きなラーメンスロットの値をセットします.文脈情報の値は,*<キー名>で,条件やアクションの中で取り出せます.
get_ramen_location(*topic_ramen, &location)は,開発者の作成した関数の呼び出しです.get_ramen_locationはscenario_functions.pyで定義されています.この関数は第1引数の値であるラーメンの種類が名物である場所を検索し,文脈情報の第2引数で指定されたキーの値にセットします.例えばtopic_ramenキーの値が味噌ラーメンの場合,味噌ラーメンが名物である場所を検索し,その値が札幌であれば,文脈情報のlocationの値を札幌に設定する,という処理を行います.
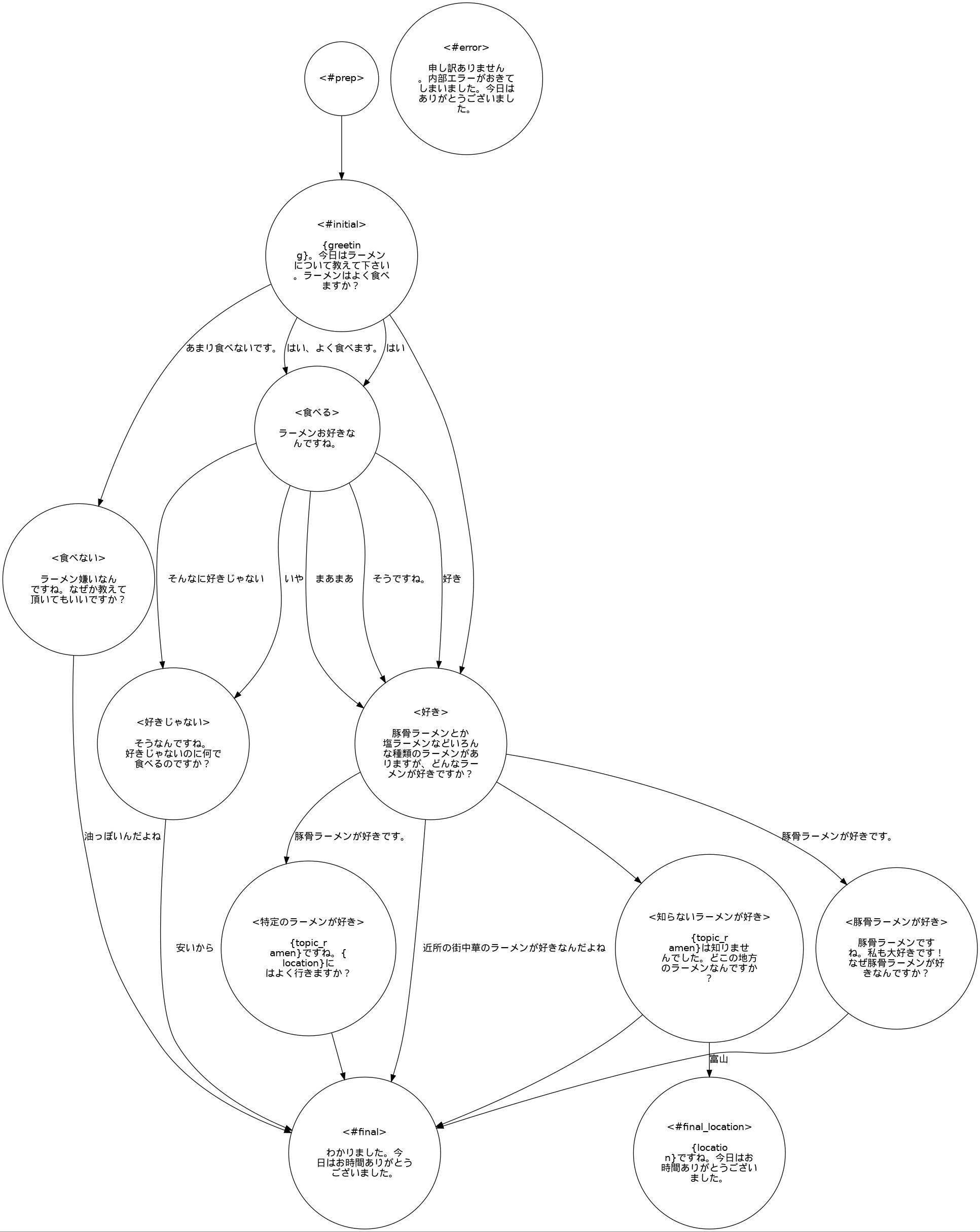
3.4.4.5. 遷移の記述のまとめ
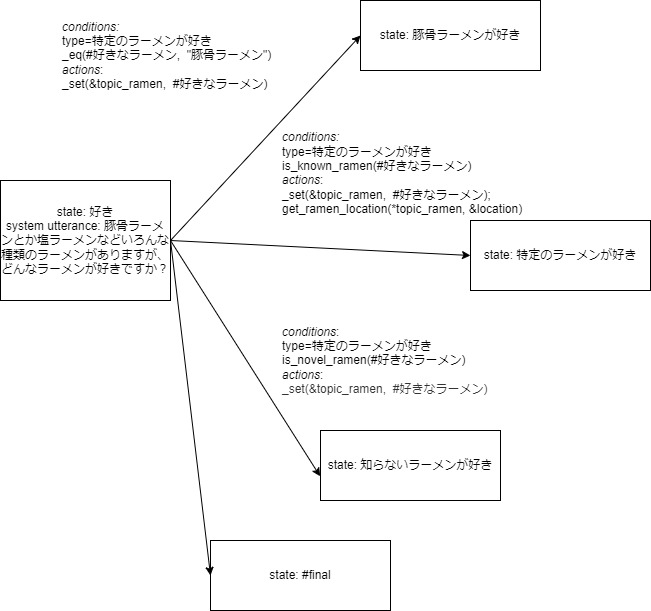
まとめると,1行目は,状態が好きの時,「豚骨ラーメンとか塩ラーメンなどいろんな種類のラーメンがありますが,どんなラーメンが好きですか?」を発話し,次のユーザの発話の言語理解結果のタイプが特定のラーメンが好きで,好きなラーメンスロットの値が豚骨ラーメンであれば,条件が満たされて遷移が行われ,好きなラーメンスロットの値,すなわち,豚骨ラーメンが,文脈情報のtopic_ramenの値にセットされ,豚骨ラーメンが好き状態に移行します.条件が満たされない場合,2行目の条件が調べられます.
これを図示すると以下のようになります.
3.4.4.6. 特殊な状態名
状態名には特殊なものがあります.
#prepは,対話が始まる前の状態で,セッション開始後,条件判定とアクションが実行されます.
#initialは,最初のユーザ発話を生成する状態です.
#finalで始まる名前の状態は,最終状態です.ブロックの出力のfinalにTrueを入れて返すので,対話が終了します.
#errorは,内部エラーが起きた場合に遷移する状態です.これもブロックの出力のfinalにTrueを入れて返します.
3.4.4.7. シナリオグラフ
Graphvizがインストールされていれば,アプリケーションを起動したとき,system utterance列のシステム発話とuser utterance example列のユーザ発話例を利用したグラフ(シナリオグラフ_scenario_graph.jpg)を出力します.以下が本アプリケーションのシナリオグラフです.
3.4.5. N-Best言語理解結果の利用
本アプリケーションでは,LR-CRF言語理解ブロックが5-Bestの理解結果を出力するようになっています.これは,コンフィギュレーションファイルの以下のnum_candidates要素で指定されています.
blocks: # bclock list
- ....
- name: understander
....
num_candidates: 3
- ....
STN Managerブロックでは,遷移の条件を調べるときに上位の言語理解結果から順に調べ,条件を満たすものがあれば.その結果を用いてアクションを実行して,次の状態に遷移します.
3.4.6. シンプルアプリケーションを利用したアプリケーション構築
3.4.6.1. 概要
{}3.3.2 章と同様に,シンプルアプリケーションを利用したアプリケーション構築法を説明します.
sample_apps/simple_jaをディレクトリ毎コピーします.DialBBのディレクトリとは全く関係ないディレクトリで構いません.各ファイルを編集します..これらのファイルの名前を変更しても構いません.
以下のコマンドで起動します.
export PYTHONPATH=<DialBBディレクトリ>;python run_server.py <コンフィギュレーションファイル>
3.4.6.2. 変更するファイル
simple-nlu-knowledge-ja.xlsxLR-CRF言語理解ブロックで用いる知識を編集します.
simple-scenario-ja.xlsxシナリオを編集します.
scenario_functions.pyシナリオに付け加えた関数(条件関数,アクション関数)の定義を行います.(5.5.6.4 章参照.)
各関数の定義では,シナリオで用いる引数にプラスして,文脈情報を表す辞書型の引数を付加する必要があります.一般的には,
context: Dict[str, Any]とします.文脈情報には,あらかじめ登録されている情報と対話中にアクション関数によって登録される情報があります.詳細は5.5.4.1 章を見てください.config.yml基本的な機能のみを用いるならば,あまり変更する必要はないと思います.
3.5. 実験アプリケーション
3.5.1. 概要
ChatGPTによる言語理解・固有表現抽出とネットワークベース対話管理を軸に,組み込みブロックの様々な機能を含んでいるものです.以下の組み込みブロックを用いています.
シンプルアプリケーションとの大きな違いは,ChatGPT言語理解ブロックとChatGPT固有表現抽出ブロックを用いているところと,STN Managerブロックの先進的な機能を用いているところです.
3.5.2. アプリケーションを構成するファイル
本アプリケーションを構成するファイルはsample_apps/simple_jaディレクトリ(フォルダ)にあります.そのディレクトリには以下のファイルが含まれています.
config.ymlアプリケーションを規定するコンフィギュレーションファイルです.
lab_app_nlu_knowledge_ja.xlsxChatGPT言語理解ブロックで用いる知識を記述したものです.
lab_app_ner_knowledge_ja.xlsxChatGPT固有表現抽出ブロックで用いる知識を記述したものです.
lab_app_scenario_ja.xlsxSTN Managerブロックで用いる知識を記述したものです.
scenario_functions.pySTN Managerブロックで用いるプログラムです
test_requests.jsonテストリクエスト(4.8 章)のファイルです.
3.5.3. ChatGPT言語理解ブロック
ChatGPTのJSONモードを用いて言語理解を行います.言語理解用の知識はLR-CRF言語理解ブロックと同じ形式のものを用います.これをFew-shot learningに用いて,入力テキストに対して言語理解を行います.入出力LR-CRF言語理解ブロックも同じです.
GPTのモデルは,ブロックコンフィギュレーションのgpt_modelで指定しています.
ChatGPTに言語理解を行わせる場合のプロンプトのテンプレートはデフォルトのものを用いていいます.詳細はchatgpt_understander_paramsを参照してください.
3.5.4. ChatGPT固有表現抽出ブロック
ChatGPTを用いて固有表現抽出を行います.抽出した結果は,ブロックの出力のaux_dataに入れて返します.以下が例です.
{"NE_人名": "田中", "NE_地名": "札幌"}
人名や地名は以下に述べる固有表現抽出知識で定義されている固有表現のクラスです.この結果はSTN Managerブロックの中で,#NE_人名や#NE_地名という特殊変数で取り出すことができます.
3.5.4.1. 固有表現抽出知識
ChatGPT固有表現抽出ブロックが用いる知識は,simple-ner-knowledge-ja.xlsxに書かれています.固有表現抽出知識の記述法の詳細は5.7.3 章を参照してください.以下に簡単に説明します.
固有表現抽出知識は,以下の2つのシートからなります.
シート名 |
内容 |
|---|---|
utterances |
発話例と,その発話例から抽出されるべき固有表現 |
classes |
固有表現のクラスの説明とそのクラスの固有表現の例 |
utterancesシートの一部を以下に示します.
flag |
utterance |
entities |
|---|---|---|
Y |
札幌の味噌ラーメンが好きです |
地名=札幌 |
Y |
田中です |
人名=田中 |
Y |
太郎は東京に住んでます |
人名=太郎,地名=東京 |
flag列は,その行を使用するかどうかをコンフィギュレーションで規定するためのものです.utterance列は発話例です.entitiesには,<固有表現クラス名>=<固有表現>, ... ,<固有表現クラス名>=<固有表現>の形で発話に含まれるスロットを書きます.カンマは全角でも読点でも構いません.
以下はclassesシートの例です.固有表現のクラス毎に1行記述します.
flag |
class |
explanation |
examples |
|---|---|---|---|
Y |
人名 |
人の名前 |
田中,山田,太郎,花子,ジョン |
Y |
地名 |
場所の名前 |
札幌,東京,大阪,日本,アメリカ,北海道 |
flag列は,utterancesシートと同じです.class列には固有表現のクラスを書きます.explanation列には固有表現の説明を書きます.examples列には,そのクラスの固有表現の例をカンマまたは読点で並べて書きます.
3.5.5. STN Managerの機能
実験アプリケーションでは,シンプルアプリケーションでは用いていない以下のSTN Managerの機能を使っています.
3.5.5.1. システム発話中の関数呼び出し・特殊変数参照
シンプルアプリケーションでは,システム発話中には,文脈情報の変数しか埋め込んでいませんでしたが,関数呼び出しや特殊変数も埋め込むことができます.
例えば,
私は{get_system_name()}です.よろしければお名前を教えて頂けますか?
の場合,scenario_fuctions.pyで定義されているget_system_name(context)が呼ばれ,その返り値(文字列)が{get_system_name()}に置き換わります.なお,get_system_nameは,コンフィギュレーションファイルのsystem_nameの値を返すように定義されています.
ありがとうございます.{#NE_人名}さん,今日はラーメンについて教えて下さい.ラーメンはよく食べますか?
の場合,{#NE_人名}は,特殊変数#NE_人名の値で置き換えられます.#NE_人名はaux_dataのNE_人名の値,すなわち固有表現抽出の人名の値になります.
3.5.5.2. シンタクスシュガー
シナリオ内で組み込み関数呼び出しを簡単に記述するためのシンタクスシュガーが用意されています.たとえばconfirmation_request="すみません.ラーメンってよく食べますか?"は_set(&confirmation_request, "すみません.ラーメンってよく食べますか?")と同じです.
#好きなラーメン=="豚骨ラーメン"は,_eq(#好きなラーメン, "豚骨ラーメン")と同じで,#NE_人名!=""は,_ne(#NE_人名, "")と同じです.
3.5.5.3. リアクション発話生成
シナリオのactions欄に_reaction="そうなんですね."があります._reactionは文脈情報の特殊な変数で,次のシステム発話の先頭にこの変数の値を付加します.たとえば,この後状態好きに遷移すると,システム発話豚骨ラーメンとか塩ラーメンなどいろんな種類のラーメンがありますが,どんなラーメンが好きですか?の先頭に,そうなんですね.が付加され,そうなんですね.豚骨ラーメンとか塩ラーメンなどいろんな種類のラーメンがありますが,どんなラーメンが好きですか?が発話されます.
このようにユーザ発話に対するリアクションを与えることで,ユーザの言ったことを聞いているよ,ということを示すことができ,ユーザ体験が良くなります.
3.5.5.4. ChatGPTを用いた発話生成・条件判定
システム発話中にある,$ユーザ発話に対する感想を言って対話を終わらせる短い発話を生成してください.$"は,組み込み関数呼び出し{_generate_with_llm("それまでの会話につづけて,対話を終わらせる発話を50文字以内で生成してください."}のシンタクスシュガーで,ChatGPTを用いて発話を生成します.
また,conditions欄にある$ユーザが理由を言ったかどうか判断してください.$は,組み込み関数呼び出し_check_with_llm("ユーザが理由を言ったかどうか判断してください.")のシンタクスシュガーで,これまでの対話からChatGPTを用いて判定を行い,bool値で返します.
また,システム発話中にある以下の,$$$...$$$の囲まれた部分は,組み込み関数呼び出し{_generate_with_prompt_template(...)}のシンタクスシュガーで,囲まれた部分をプロンプトテンプレートとし,{..}`のプレースホルダを置き換えた上でChatGPTに発話生成をさせます.
$$$
# 状況
{situation}
# あなたのペルソナ
{persona}
# 現在までの対話
{dialogue_history}
# タスク
それまでの会話につづけて,対話を終わらせる発話を50文字以内で生成してください.
$$$
発話を生成する際のChatGPTのモデルや温度パラメータ,状況設定,ペルソナはブロックコンフィギュレーションで以下のように指定されています.
chatgpt:
gpt_model: gpt-4o-mini
temperature: 0.7
situation:
- あなたは対話システムで,ユーザと食べ物に関して雑談をしています.
- ユーザとは初対面です
- ユーザとは同年代です
- ユーザとは親しい感じで話します
persona:
- 名前は由衣
- 28歳
- 女性
- ラーメン全般が好き
- お酒は飲まない
- IT会社のwebデザイナー
- 独身
- 非常にフレンドリーに話す
- 外交的で陽気
3.5.5.5. サブダイアローグ
next state欄に#gosub:確認:ラーメン食べるか確認完了があります.これは,確認状態に遷移して対話を行った後,ラーメン食べるか確認完了状態に戻るという意味です.確認状態から始まる対話をサブダイアローグと呼びます.サブダイアローグが#exit状態に移行すると,サブダイアローグから抜けて,ラーメン食べるか確認完了状態に行きます.
ユーザに確認を行うような,いろいろな場面で再利用可能な対話を,サブダイアローグとして用意しておくことで,シナリオ記述を減らすことが可能です.
3.5.5.6. スキップ遷移
system utterance欄に$skipがあるとシステム発話を返さず,すぐに条件判定を行って次の遷移を行います.アクションの結果をもとにさらに遷移先を変えたいときなどに使います.
3.5.5.7. リピート機能
ブロックコンフィギュレーションでrepeat_when_no_available_transitionsが指定されています.これが指定されているとき,条件を満たす遷移がなければ,元の状態に戻って同じ発話を繰り返します.この場合,デフォルト遷移がない状態があっても構いません.本アプリケーションの場合,好き状態にはデフォルト遷移がないので,この状態で全く関係ない発話をした場合には,同じシステム発話が繰り返されます.
3.5.5.8. 音声入力に対処するための機能
STN Managerには音声入力に対処するための機能があり,ブロックコンフィギュレーションで設定することで利用できます.本アプリケーションでは以下のように設定しています.
input_confidence_threshold: 0.5
confirmation_request:
function_to_generate_utterance: generate_confirmation_request
acknowledgement_utterance_type: 肯定
denial_utterance_type: 否定
ignore_out_of_context_barge_in: yes
reaction_to_silence:
action: repeat
これらの意味は5.5.12 章を見てください.
test_requests.jsonには音声入力に対応した入力の例が入っています.